Versent at DataEngBytes 2025

Kovid Rathee
Principal Solutions Architect, Data & Insights
Kovid Rathee
Principal Solutions Architect, Data & Insights
Two days in the life of Data and AI engineers
The Versent Data & Insights attended the main data engineering event of the year in Melbourne in late July. The conference caught my interest last year when they invited Chip Huyen, author of the book AI Engineering, for a talk. When I found out our team was going to the event, I checked the schedule of the two parallel tracks and immediately decided which talks were not to be missed and which ones I could probably skip.
During the two days, I ended up attending thirteen sessions and might have listened to a couple of others in bits and pieces. In my reading, Track 1 was mostly L100-type talks, although there were some exceptions. Track 2 was where L200 and, in some cases, L300 sessions were taking place. This blog post is a brief account of the two-day event, highlighting the aspects I enjoyed most. Here we go, session by session!
Building Trino Data Pipelines with SQL or Python
I started with Lester Martin’s session, Building Trino Data Pipelines with SQL or Python, which was quite good. Lester took us through the history of Presto, how it compared to Spark, how it wasn’t a compute engine but a query engine, among other things, before he drew our attention to the complexities of a typical distributed ETL workflow, highlighting shuffles, sorts, partitions, stages, and whatnot.

Lester also highlighted how Trino’s fault-tolerant execution model, along with the support for both SQL and Python, more or less, covered the linguistic reach of the data engineering community. Then there are rebels who want to use Rust; it is becoming a thing anyway, but I’ll leave that to another day. One of the things Lester said was really funny and really true, which was that even the data engineers who primarily use Python DataFrames end up using the .sql() syntax more often than not. SQL is such a simple and beautiful language. He said:
We all like SQL or we hate SQL, but we all use SQL.
Lester focused on writing SQL, which may not be necessary with Starburst’s (Trino’s managed data lakehouse solution) Python libraries: PyStarburst and Ibis. These libraries provide PySpark-like syntax, lazy evaluation, and the Python code you write is automatically converted into SQL, which means that most of the heavy lifting is then handled by Trino itself. It is important to note, though, that PyStarburst is only supported by Starburst Galaxy and Starburst Enterprise. I won’t go into much more detail about Ibis, but a good starting point if you’re interested in learning about Trino would be the following two links:
Streaming Analytics with Apache Polaris
The next session was led by Kamesh Sampath, a Lead Developer Advocate at Snowflake, who discussed using a fully open-source stack to create a streaming analytics dashboard—the stack he used:
- Kafka — for publishing real-time events on topics
- RisingWave — the streaming data lakehouse platform
- Polaris — the catalog for registering and discovering tables
- Iceberg — the table format used for organizing Parquet files
- Streamlit — the analytics application engine
The session focused on the idea of avoiding being locked into any particular technology and utilizing open standards and open-source technologies whenever possible. Polaris is the base for Snowflake’s Open Catalog and Snowflake Horizon Catalog. The open-source version of Polaris can be run on a small, simple server anywhere. It is language-agnostic and vendor-neutral, and focuses on metadata portability.
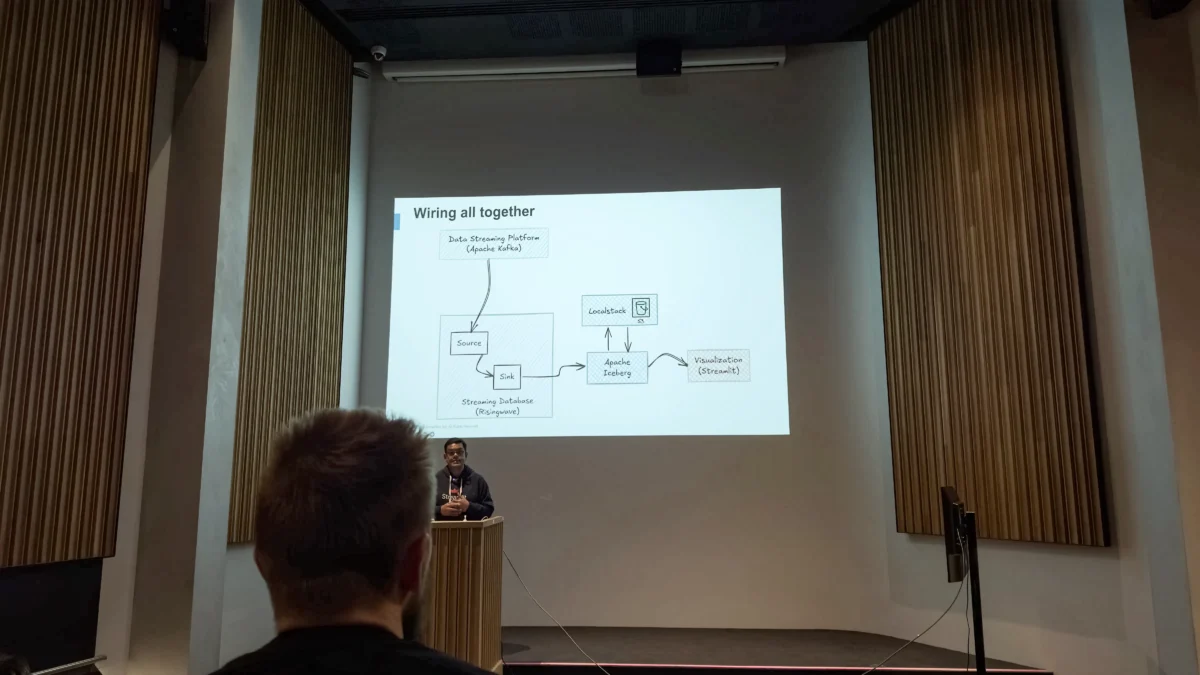
It was a fun, fully functional and working demo, which, if you’re a data engineer, you probably know is a rarity. Find more about Kamesh’s work here.
Simplifying Data Pipelines with Tableflow
The next session was led by Confluent’s Prerna Tiwari, who took us through a Kafka-native, serverless, managed stream-to-table data pipeline service, emphasizing that managing streams is very difficult with traditional batch-based or micro-batch-based pipelines. Tableflow takes a declarative approach to data pipelines, which is where the data engineering world is going. Databricks also recently announced Lakeflow Declarative Pipelines.

Tableflow, in effect, bypasses all other data lakehouse ingestion patterns and feeds data directly into your data lakehouse, built on Iceberg or Delta Lake tables, essentially getting rid of the process of converting topics into schemas, which, as you would know, can be quite messy with evolving schemas. Tableflow was announced last year, and it is GA as of March 2025. Tableflow also integrates with Databricks, Snowflake, Trino, and other data platforms. The following image compares open table formats, stream-to-table data lakehouse solutions, general-purpose ETL solutions, and Tableflow on a range of features and capabilities.

On Creating a Data Catalog by Accident
This was probably one of the best, certainly the funniest, and most relatable sessions of the two days. May-Lyn Hu, a Data Lead at Pet Circle, presented a session with the following title: Automate Your Metadata, Deliver a Data Catalogue (by accident).

May-Lyn perfectly captured the need for a data catalog by highlighting all the unnecessary conversations, bottlenecks, and frustrations people have gone through just to get an answer to what would seem to the business a fairly simple question!
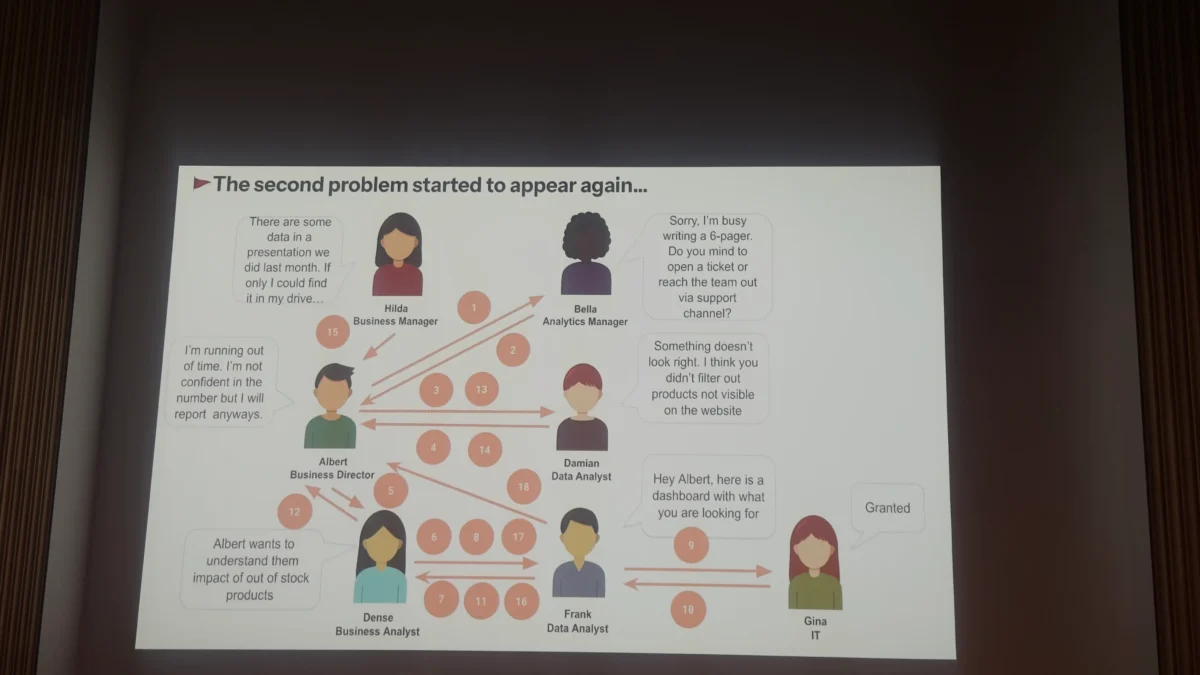
This led to the team asking the question — is this (cataloging) a solved problem? The answer was yes, but it was cost-prohibitive, or at least it was going to be significantly if not prohibitively expensive, as she cited a $1500 seat price. So, the real answer was to conceptually break down what a catalog is from a first principles approach. The team did that and determined that it was just a collection of metadata that needed to be maintained in a structured manner. The team chose YAML. This didn’t come without challenges, but the team successfully delivered a data engineer-facing catalog.

What about the business? Wasn’t the actual problem that the business doesn’t know where data assets are, what they mean, and whether they can be trusted? Yes, it was. So, the team decided to build a frontend for the business, too. This frontend gave the business a way to search data assets, access their quality and trust scores, look up ownership and stewardship metadata, among other things.
May-lyn stressed that it wasn’t an easy journey to build this. It took about a year to build the backend and the frontend, which essentially means that this is not for everyone, a point I completely agree with. However, I also think that businesses with the engineering skillset and drive to pull this off should consider doing so.
Problems That You Only Face with Scale
The next session focused on a cost-optimization project at Block following their acquisition of Afterpay. It’s a story of how the data team reduced the data egress cost for their cross-region data processing set up by over half a million USD per year. The following is from the Cash App blog. It should give you an idea of the scale:
Kafka pipelines managed by the Afterpay data team process over 9 TB of data daily and deliver data to critical business domains such as Risk Decisioning, Business Intelligence and Financial Reporting via ~200 datasets. In the legacy design, duplicate events from Kafka’s “at least once” delivery required downstream cleansing by Data Lake consumers and late-arriving records added substantial re-processing overheads.
The talk brought back some memories of dealing with scale (although nowhere close to this), reading about the journey of other teams on blogs like High Scalability. To know more about the challenge and solution at Afterpay, head over to the blog post for Project Teleport: Cost-Effective and Scalable Kafka Data Processing at Block.
How to Build an Agent
Geoffrey Huntley, who’s an AI engineer at Sourcegraph, came in with a single goal — to convince everyone that they could build their code-editing agents and it wasn’t that difficult. Because I had built something of that sort, although without using MCP, I already knew that point he was trying to make. Nevertheless, it was good to see how simple an agent can be — essentially, a self-referencing agent completion request in a while loop.

Sourcegraph has released its agentic coding tool called Amp, which is a Cursor and Windsurf alternative. There are some key distinctions between, say, Cursor and Amp:
- With Cursor, you can choose models; with Amp, you cannot. Amp believes it chooses the best models.
- Amp doesn’t have any limit on token usage. Your token usage decides how much you pay.
- Amp is also collaborative — it lets you share threads with other team members and collaborate with them.
It’s an interesting approach to code editors. If you want to know more about Amp, I can point you to the following two resources:
The entire slide deck that Geoffrey used during his presentation is also available on his blog.
PromptSQL — Using LLMs for Query Optimization
And then, towards the end of Day 2, on centre stage, Versent’s own Jake Kerr shared his thoughts and experiences in using LLMs for query optimization. Jake broke down the problem of query optimization and told the audience how it’s not going to go away. Rather, he walked everyone through a step-by-step plan of optimizing queries using structured prompts created for investigating query optimization issues, highlighting those issues right within your SQL IDE, and then fixing those issues one by one.
The focus of this session was to highlight that raw prompting alone cannot get you very far with query optimization. But if you break down the problem into manageable chunks and use something like LangGraph to manage the state of the activities, you might be able to do that.

Query optimization is just another code analysis problem that can and should be broken down into multiple steps, each of which can be assigned to several agents, each with its own separate tools. Uber’s QueryGPT is a good example of this. It uses several types of agents: intent agent, table agent, column pruning agent, among other intermediate agents.

The Database Group at the University of Pennsylvania also found that LLMs are unreasonably effective with query optimization, although this wasn’t necessarily an agent-based assessment. Find more about the LLMSteer project presentation here and the associated code here on GitHub.
Jake concluded his remarks by sharing some time-tested query optimization principles and rules of thumb, which I’ll repeat here for you: join reordering based on real cardinality, predicate pushdown, set-based replacements, redundancy elimination, and data type mismatches.
All in all, these were two days well spent with the team, meeting former colleagues, ISV partners, and dabbling in the interesting tools and technologies, and hearing stories of daily struggles, architectural best practices, and challenges of scale, among other things. I think it’s an event worth attending, regardless of your level in data engineering, ML, or AI.
Epilogue
Jake’s session marked the end of the two-day data engineering, ML, and AI fun getaway for the team. I stayed back for the after-party at Melbourne Park for a while. And then left for an even cooler Friday night event at the University of Melbourne, where Dr. Danielle Holmes, who is the Women in Physics Lecturer at the Australian Institute of Physics, was presenting the Marie Curie lecture as part of the July Lectures in Physics—the topic of her presentation, Quantum Century: Unlocking the Universe’s Secrets and Shaping our Future.
Dr. Holmes talked about 100 years of quantum theory and walked us through the history of how the theory came to be. She spoke about its practical importance in explaining phenomena like why birds don’t get lost in long migrations, how stars shine, among other things. She then ventured into the future of quantum computing and how it will be critical to solving many of the world’s seemingly unsolvable problems, such as climate change, nuclear energy, molecular simulation, advanced cryptography, and machine learning. Those in Sydney can still catch the same lecture as part of the National Science Week. Details here.
