5 ways to reduce your data platform costs.
Simeon Lobo
Principal Consultant, Data & Analytics
Simeon Lobo
Principal Consultant, Data & Analytics
The team at Amazon are continuously releasing new updates to Redshift that reduce overall costs, whilst improving performance, scalability, ease of use and Data Lake integration.
Our Versent Data Advisory and Managed Services teams continuously monitor, test and prototype these Redshift platform innovations with the intent of guiding clients towards realising the immediate business benefits in terms of cost and performance management.
We believe that clients can realise between 20% – 60% reduction in their Redshift spend by employing some of the proven techniques below.
Please reach out to us at info@versent.com.au if you would like to chat with our Data & Analytics Team to learn more.
As of this writing, the top five ways we’ve successfully slashed Redshift run costs are:
Tip 1 – Pausing and Resuming Redshift non-prod clusters
While Production Redshift clusters in enterprises are typically run all the time, this is not required for Development, UAT or Pre-PROD environments. It simply does not make sense to accrue costs when these non-PROD environments are not being used, especially over weekends and the longer business holiday periods.
Historically, we’ve written scripts to implement this Pause and Resume functionality for our clients. This involved backing up the Redshift cluster, terminating it and restoring the cluster from the snapshot before it is next required.
You no longer need these manual workarounds as AWS now provides us the ability to Pause and Resume the Redshift cluster via the AWS Management Console and/or CLI commands. While a cluster is paused, on-demand compute billing is suspended, while storage costs are still incurred.
Below are some screenshots of implementing this Pause and Resume functionality via the AWS Management Console. For more information about this feature, please visit https://docs.aws.amazon.com/redshift/latest/mgmt/managing-cluster-operations.html#rs-mgmt-pause-resume-cluster

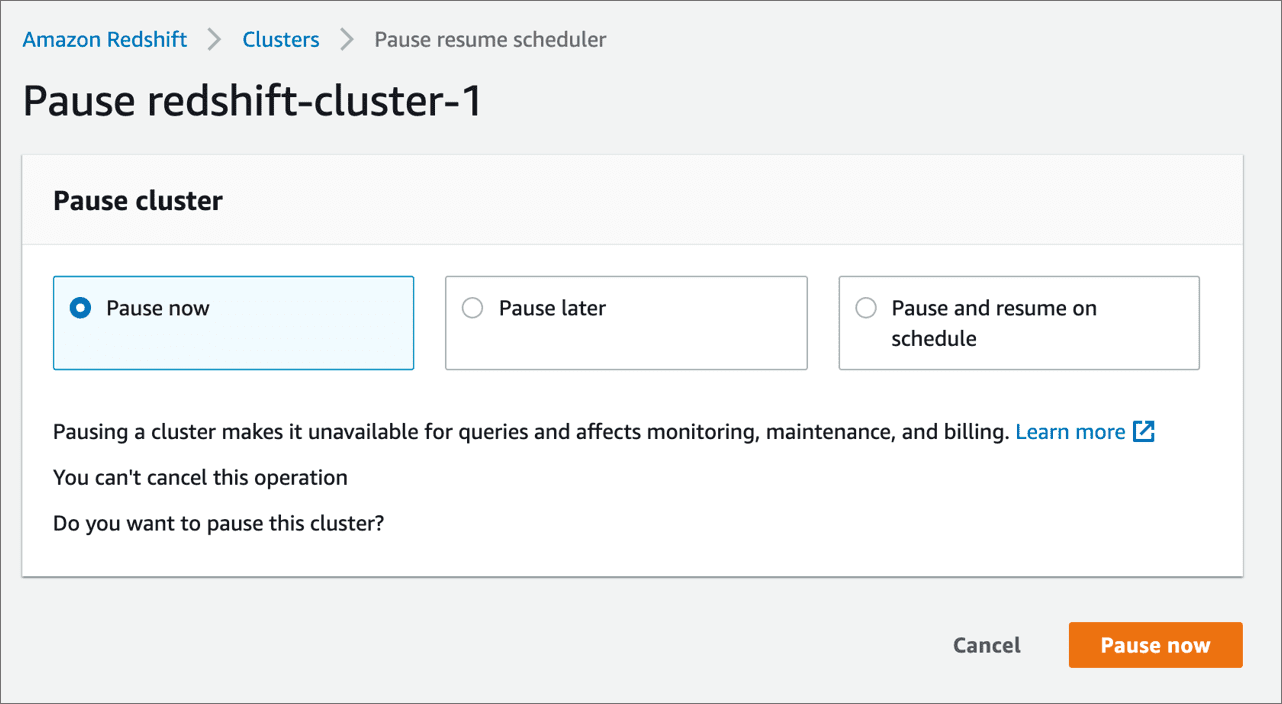
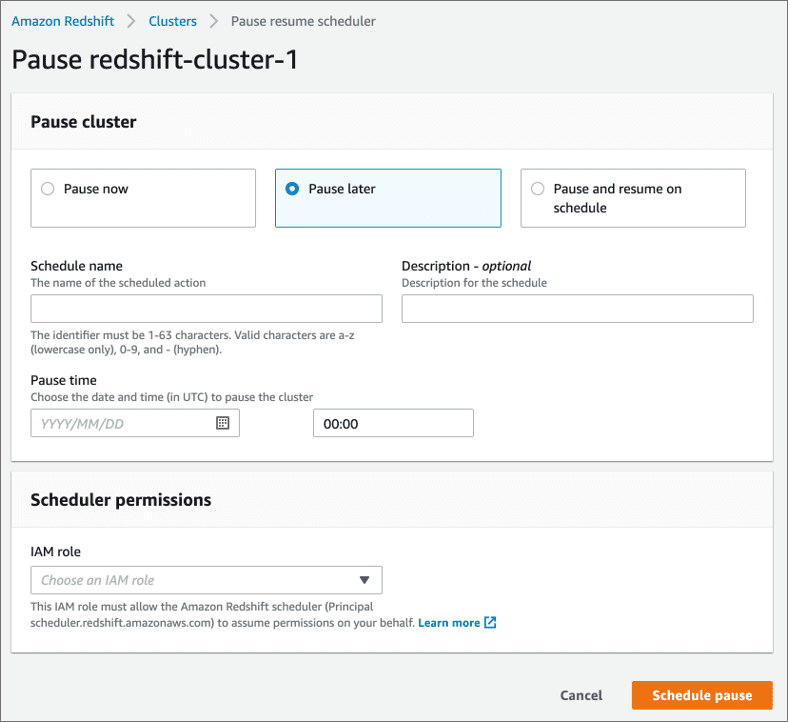

Tip 2 – Leverage concurrency scaling
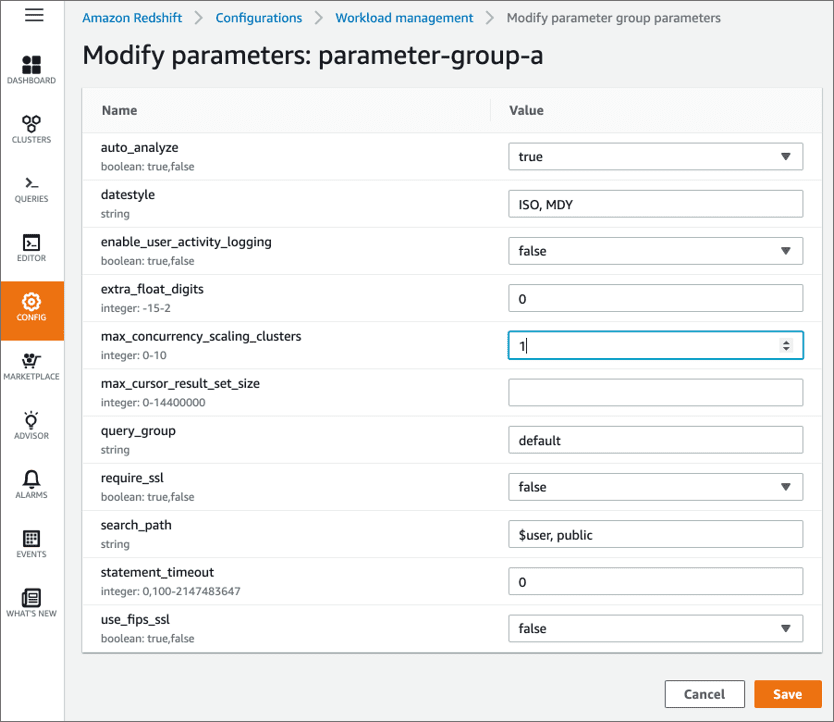
The concurrency scaling feature in Redshift allows for the elastic scaling, up and down, of a set of “concurrency clusters” that are separate from the main cluster to manage short-burst read requests. Write operations still run on the main cluster. Costs are accrued on a per-second basis for the uptime of each concurrency scaling cluster (we can provision 1 – 10 of these clusters as shown in the screenshot below). In most cases, cost savings result from AWS providing 1 hour of free concurrency scaling credits for every 24 hours that the main cluster runs. With careful workload management planning and variance prediction in ETL, BI and Data Science workloads, concurrency scaling can end up being free for most Redshift clients due to the available free credit limit.
Below is a screenshot of the Redshift configuration page to adjust the number of concurrency scaling clusters in the AWS Management Console. For more information about concurrency scaling, please visit https://docs.aws.amazon.com/redshift/latest/dg/concurrency-scaling.html
Tip 3 – Use AZ64 compression encoding
The new AZ64 compression encoding introduced by AWS has demonstrated a massive 60%-70% less storage footprint than RAW encoding and is 25%-35% faster from a query performance perspective. While comparing the 9 different encoding types available in Redshift, we found that the best way to measure the effectiveness was to look at both the storage and the query processing times together, and not each in isolation. Under the hood, through Amazon’s ongoing Redshift innovation initiatives, AZ64 leverages the new SIMD instructions in modern processors to drive specialised parallel processing. These improvements directly impact the cost of storing and querying data stored in Redshift.
AZ64 compression encoding can only be used with the following data types:
- SMALLINT
- INTEGER
- BIGINT
- DECIMAL
- DATE
- TIMESTAMP
- TIMESTAMPTZ
To use AZ64 compression encoding, just add the encoding type as shown below to your CREATE TABLE or ALTER TABLE scripts:

Tip 4 – Using materialised views and unloading complex query results to S3 for query via Athena
Materialised views provide us with the ability to create a view by pre-computing results once and then querying this result many times. This is especially useful for complex queries. To further save costs, Data Architects may decide to UNLOAD the results of these complex queries to S3 for serverless, price-per-query consumption via Amazon Athena.
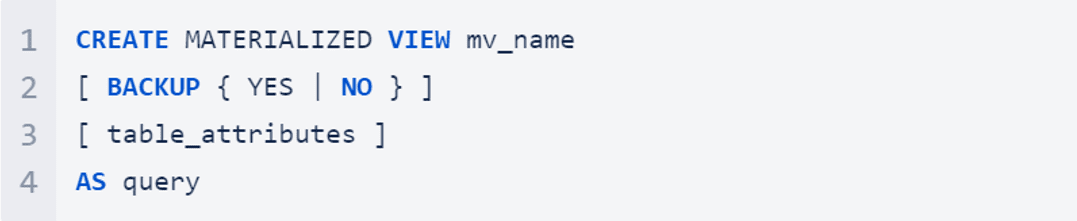
Creating a materialised view is as simple as running the below:
To UNLOAD results of a query to S3 by partition and in .parquet format:

Tip 5 – Take advantage of behind the scenes Machine Learning-based automations
The overhead costs to run and maintain a Redshift cluster are continuously reducing, as AWS automates several administration tasks via Machine Learning. These Machine Learning algorithms automatically optimise Redshift’s performance, automate tasks and provide prescriptive recommendations via Advisor capabilities.
Several admin features that have now been automated by leveraging these new capabilities include automatic:
- Analyse
- Vacuum delete
- Table sort
- Table distribution style, and
- Distribution / sort key advisors
Personnel who were previously tasked with Redshift administration can now focus their valuable time on extracting business value from data stored in Redshift.
If you would like to explore how your organisation can better utilise AWS Redshift, or if you have any queries about advancing your data and analytics capabilities, request to chat to one of our data engineers at info@versent.com.au.
Simeon Lobo – LinkedIn
Whitepaper

Overseeing vs Overlooking AI
Versent’s white paper explores the growing gap between AI ambition and operational reality and why monitoring alone isn’t enough. Download it now for a practical view of AI observability, governance, and how to stay confident in what your AI is doing.