RAG For Private Documents in 10 Minutes

Jimmy Sun
Senior Engineer
Jimmy Sun
Senior Engineer
Introduction
With Retrieval Augmented Generation (RAG), users’ questions of a specific domain can be answered by a generative Large Language Model (LLM) rather than relying on expert systems. In a typical RAG solution, the domain knowledge is stored in a vector database and searched in real-time, allowing the LLM to provide more accurate and contextually relevant responses. With minimal effort, you can index your private documents using the Azure AI Search service as the vectorized knowledge base and create a .NET console app to query those indexed private documents.
Why RAG?
Generative LLMs are powerful in solving problems and generating human-like answers. However, they have several limitations, which RAG can help overcome.
Limited Context Size
The context window of an LLM, usually used to store conversation history, is analogous to the cache of a CPU. However, knowledge mining targets much larger datasets, such as years of financial records, which cannot fit into the context window. By introducing a retrieval mechanism, RAG allows the LLM to access relevant information from a vast knowledge base.
Out-of-date Responses
In addition to the context size limit, LLMs are trained with existing/old data. However, some applications require the latest information, such as booking flight tickets, and LLMs cannot respond promptly. RAG enhances LLMs by retrieving real-time information, ensuring that applications can address users’ queries with historical and current information.
Lack of Custom Knowledge
Most popular LLMs are trained with public data and may lack specific domain knowledge, such as private databases or internal documents. RAG allows the integration of custom domain knowledge by indexing private documents and specialized datasets. This ensures the LLM can provide expertise tailored to specific industries or fields.
Vectorized Knowledge Base
If the LLM was the cortex of a brain, i.e., to recall/think/decide, RAG would be the hippocampus for memory storage and retrieval. A vectorized “memory storage” can be constructed using Azure AI Search service, which can have many data formats, such as PDFs, Zips, and SQL/Non-SQL databases. For simplicity, I will use web pages (HTML files) saved in blob storage to build a vectorized knowledge base.
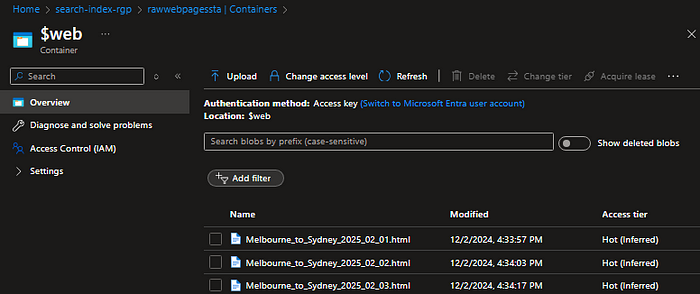
Step 1. Create a Storage Account and save web pages to a new container.
For this prototype, 3 Google Flights web pages of the Melbourne-to-Sydney trip are saved in the $web container (with static website enabled).
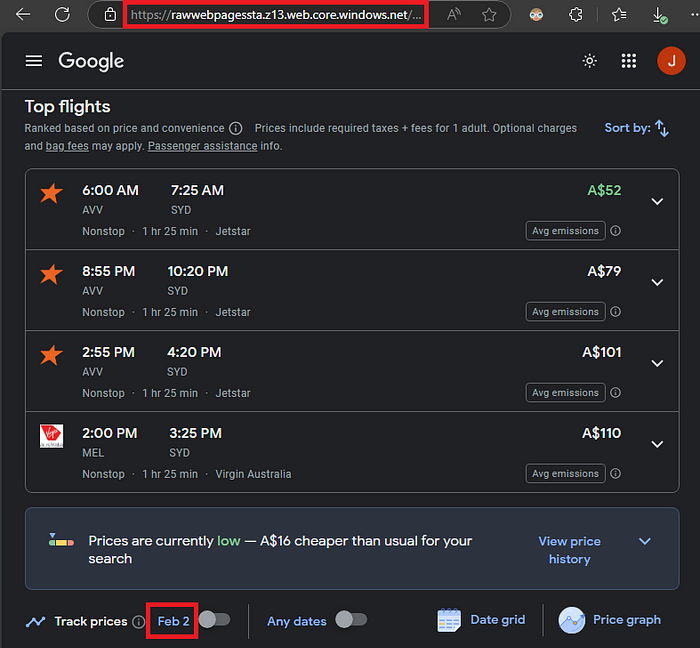
File contents (e.g., for trips on 2025-02-02):
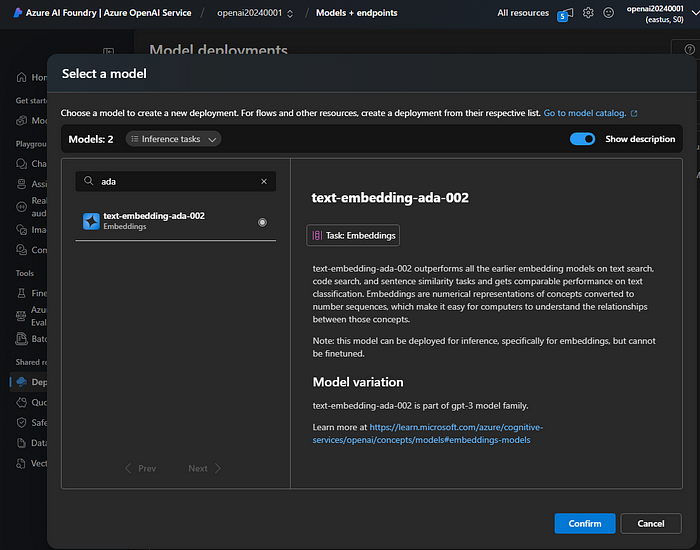
Step 2. Create an Azure OpenAI resource and deploy an embedding model from Azure AI Studio, e.g., ada-002.
Step 3. Create an Azure AI Search resource. From the overview, click on “Import and vectorize data.” Use the embedding model deployed in Step 2 to vectorize the HTML files saved in Step 1.
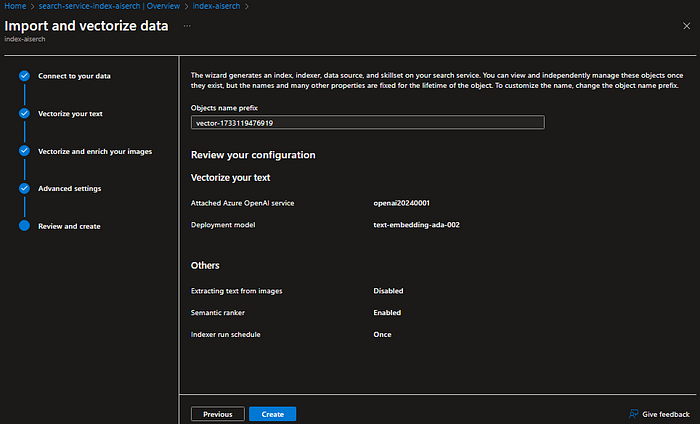
The index fields:
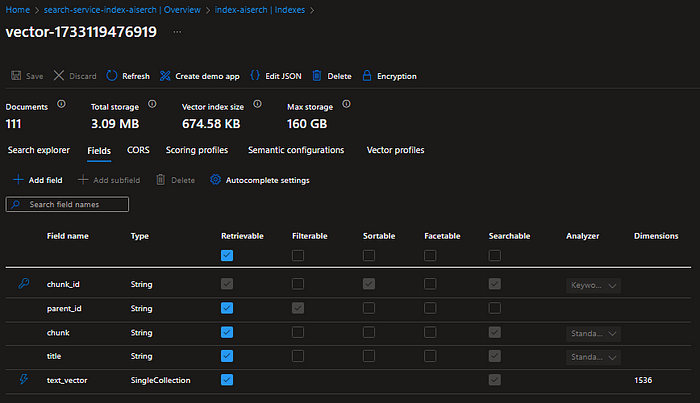
Test Vectorized Knowledge Base (Optional)
- Deploy an LLM (e.g., gpt-4o) in the Azure OpenAI resource.
- Open LLM Playground from Azure AI Studio and attach the AI Search index created in Step 3 above. You should see that the flight tickets are retrieved successfully from the data source.
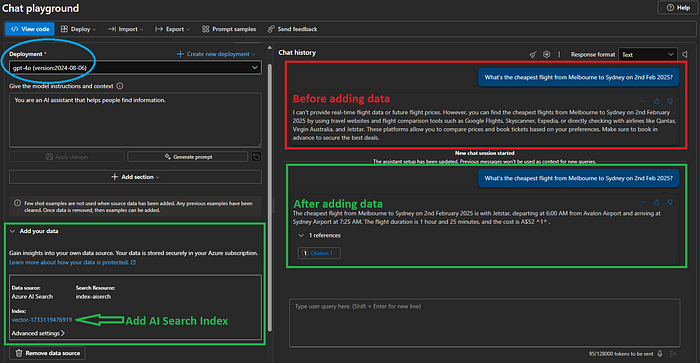
Configuring the .NET Console App
Step 1. Set the following environment variables first.
GPT_API_KEY=<OpenAI API Key>
AZURE_AI_SEARCH_URL=<Azure AI Search URL, e.g. https://xx.search.windows.net>
AZURE_AI_SEARCH_KEY=<Azure AI Search Key>
AZURE_AI_SEARCH_INDEX=<Azure AI Search Index Name, e.g. vector-xxx>
Step 2. Create a console App and add the code below to the Program.cs file.
using Azure;
using Azure.Search.Documents;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Models;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using Microsoft.SemanticKernel.Embeddings;
using Microsoft.Extensions.DependencyInjection;
using System.ComponentModel;
using System.Text.Json.Serialization;
var c = new ServiceCollection()
.AddOpenAIChatCompletion("gpt-4o", Environment.GetEnvironmentVariable("GPT_API_KEY")!)
.AddOpenAITextEmbeddingGeneration("text-embedding-ada-002", Environment.GetEnvironmentVariable("GPT_API_KEY")!)
.AddSingleton(new SearchIndexClient(new Uri(Environment.GetEnvironmentVariable("AZURE_AI_SEARCH_URL")!), new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_AI_SEARCH_KEY")!)));
c.AddKernel();
var services = c.BuildServiceProvider();
var chatService = services.GetRequiredService<IChatCompletionService>();
var kernel = services.GetRequiredService<Kernel>();
kernel.ImportPluginFromType<AISearchPlugin>();
var settings = new OpenAIPromptExecutionSettings { ToolCallBehavior = ToolCallBehavior.AutoInvokeKernelFunctions };
var history = new ChatHistory();
try
{
while (true)
{
Console.Write("Q: ");
history.AddUserMessage(Console.ReadLine()!);
var response = await chatService.GetChatMessageContentAsync(history, settings, kernel);
history.Add(response);
Console.WriteLine($"A: {response}");
}
}
catch (Exception e)
{
Console.WriteLine(e.Message);
}
// Based on https://learn.microsoft.com/en-us/semantic-kernel/concepts/plugins/using-data-retrieval-functions-for-rag
public class AISearchPlugin
{
private readonly ITextEmbeddingGenerationService _textEmbeddingGenerationService;
private readonly SearchIndexClient _indexClient;
public AISearchPlugin(ITextEmbeddingGenerationService textEmbeddingGenerationService, SearchIndexClient indexClient)
{
_textEmbeddingGenerationService = textEmbeddingGenerationService;
_indexClient = indexClient;
}
[KernelFunction("Search")]
[Description("Search for flight tickets based on the given query.")]
public async Task<string> SearchAsync(string query)
{
var embedding = await _textEmbeddingGenerationService.GenerateEmbeddingAsync(query);
var searchClient = _indexClient.GetSearchClient(Environment.GetEnvironmentVariable("AZURE_AI_SEARCH_INDEX")!);
var vectorQuery = new VectorizedQuery(embedding) { Fields = { "text_vector" } };
var searchOptions = new SearchOptions { VectorSearch = new() { Queries = { vectorQuery } } };
var response = await searchClient.SearchAsync<IndexSchema>(searchOptions);
await foreach (var result in response.Value.GetResultsAsync())
{
return result.Document.Chunk!;
}
return string.Empty;
}
private sealed class IndexSchema
{
[JsonPropertyName("chunk")]
public required string Chunk { get; set; }
[JsonPropertyName("text_vector")]
public ReadOnlyMemory<float> Vector { get; set; }
}
}
Step 3. Using the code above, you can now query your private documents from a .NET console app.

Conclusion
With a fairly small effort, you can build a RAG-powered AI solution to query your private knowledge bases. This article can be the stepping stone to kindle more creative RAG for your use cases!