How does Hive Metastore work?

Tuấn Anh Nguyễn
Engineer - Data & Insights
Tuấn Anh Nguyễn
Engineer - Data & Insights
Through the Lens of History: The Evolution of the Hive metastore from Hadoop’s Early Days to the Data Mesh Era
Hive Metastore, a backbone of modern data architecture, was born in 2007 during the early days of Hadoop. It was developed to enable Facebook engineers to write SQL-like queries (HiveQL) over the massive datasets stored in Hadoop Distributed File System (HDFS), which lacked native SQL querying capabilities at the time (Thusoo, 2009) (DataValley, 2023).
Here are some key milestones in the evolution of Hive Metastore over the past 16 years:
- 2007: Developed by Facebook Engineer — Developed by engineers at Facebook to provide a SQL-like query interface for data stored in Hadoop HDFS.
- 2008: First Open-Source Release — Maintained by Apache Software Foundation and first open-source version of Hive released (Wikipedia, 2024)
- 2008–2012: Early day of the Big Data era — Hive was designed to store information about tables, partitions, and schemas in Hadoop. It filled the gap between Hadoop and traditional Data Warehouse. Around the same time, Yahoo!, LinkedIn and Netflix also adopted Hive Metastore as part of their data architecture to scale their big data operations (The Hadoop Platforms Team, 2014) (Cockcroft, 2011) (Aditya Auradkar, 2012).
- 2012–2017: Rise of Data Lake—A Data Lake emerged as more organizations adopted Hadoop for data processing. Companies started to store their vast amounts of raw data in HDFS or cloud storage solutions like S3, GCS, or ADLS. Compute engines such as Apache Spark, Presto, and Impala started to pick up Hive Metastore as a centralized metadata service, enabling a common data access pattern across different services.
- 2017–2020: Cloud & Modern Data Warehousing—This era saw the migration from on-prem to cloud-native data warehouses. HMS became integral to large-scale cloud data lakes. In 2017, AWS introduced AWS Glue, a fully managed service that acts like Hive Metastore but is designed natively for the cloud. This service seamlessly integrates AWS services, notably Athena, Redshift, and S3. The introduction of Delta Lake and the concept of Data Lakehouse Architecture emerged in 2019 and further solidified HMS’s role in managing metadata at scale.
- 2020—Present: Data Mesh and the Next Generation of Metadata Management—While the main idea of HMS was originally designed for a centralized, monolithic data platform, its principles are still relevant in a data mesh. A consistent metadata layer remains critical for data governance and interoperability across business domains.

The next generation of metastores
- Open Metadata (2021) is a centralised metadata platform that integrates various modern data platforms and tools to manage metadata in a data mesh environment (Open Metadata, 2021).
- Databricks Unity Catalog (2022) is a unified data governance solution that builds upon Hive Metastore’s legacy to offer more robust features like fine-grained access control and auditing (Databricks, 2024).
By the end of this article, you will learn about some of the key challenges in big data, how the Hive Metastore helps solve these key challenges, and the role Hive metastore could play in modern data architecture.
Key challenges in a big data environment
To understand the Metastore, we need to understand the principal of a system database.
A system database usually consists of 3 parts:
- Storage: the data that has been stored in a file format, e.g., Parquet, ORC, Avro
- Metadata information: the metadata information, with the connection between physical data as in the file and the logical data (table name, field name)
- Compute: engine to process the data.
When a query is sent to the system, the query planner parses it and reads the metadata to find the underlying data and perform the calculation.
In an environment like Big Query (BQ), we have abstracted the underlying system, and as users, we only communicate with SQL from the front end. After the query is processed behind the scenes, the result set will be returned, and the consumer will be charged for the data scanned.
Ideally, the compute and storage systems will be separated into other Big Data systems so that the distributed system can scale separately. Data files will be stored on a distributed data storage system, e.g., HDFS or Cloud Storage (like S3, GCS, etc.), and the computation system will be set up on Cloud VMs.
Data on Cloud storage can only be displayed as files, and we have many of them in Big Data. When reading data from a single file, we will want to make it more user-friendly (logical representation) so that we can easily manage it and build the logical mappings so that people can process it.
When writing the query:
select * from catalog.schema.table;
It will look much nicer than writing the query:
select * from delta.`gs://bucket_name/bucket_subpath/schema/table/`;
For each Spark Session, a user can set a different name for any data:
create table schema.table2 using delta3location
`gs://bucket_name/bucket_subpath/schema/table/`;
The system can refer to that specific dataset within the same Spark Session using logical naming or physical location (cloud path). However, this mapping is only available for the duration of that Spark Session. It will not persist for the next one, making it non-reusable (Google Cloud, 2024).
How does Hive Metastore address this problem?
To address this challenge in a Big Data environment, the idea is to have a service that acts as an intermediary to store and map between logical address and physical table and is reused across services. This information will be stored in a database, and multiple systems can access it to have the same logical view of the dataset. That’s how the external Metastore is born. To address this need, external Metastores like the Hive Metastore (HMS) were developed,
The HMS here will act as an ORM layer (object-relational mapper). The Metadata itself can be backed by various databases (for example, MySQL, Oracle, or Postgres); however, the system interacts only with the Metadata service, abstracting away the underlying database technology.
At its core, HMS is essentially a database where metadata is stored. When a query is made, the compute engine retrieves information about where to find the related data and how it should be read. This makes it easier to manage data in a data platform and ensures consistency in the data representation across the system regardless of who or which services consume it.

In the illustration above, a data engineer will:
- Run a transformation through dbt, which submits the query to a Spark instance
- Spark will look up the information in a Hive Metastore to determine where to look for the data
- Hive retrieves the metadata stored in the MySQL database (for this example)
- Finally, Hive returns the result to Spark to process the physical data files
This interaction allows for a seamless and consistent data representation across the data system and between multiple environments.
The Hive Metastore is essential in a large-scale data platform (or Data Lake, Lakehouse). It simplifies how services within the ingestion layer and transformation layer interact with one another. Decoupling the metadata, computing, and storage enables the whole system to scale and grow independently. It ensures data governance is accessible across multiple services and sessions.
The role and values of Hive Metastores in Modern Data Architecture
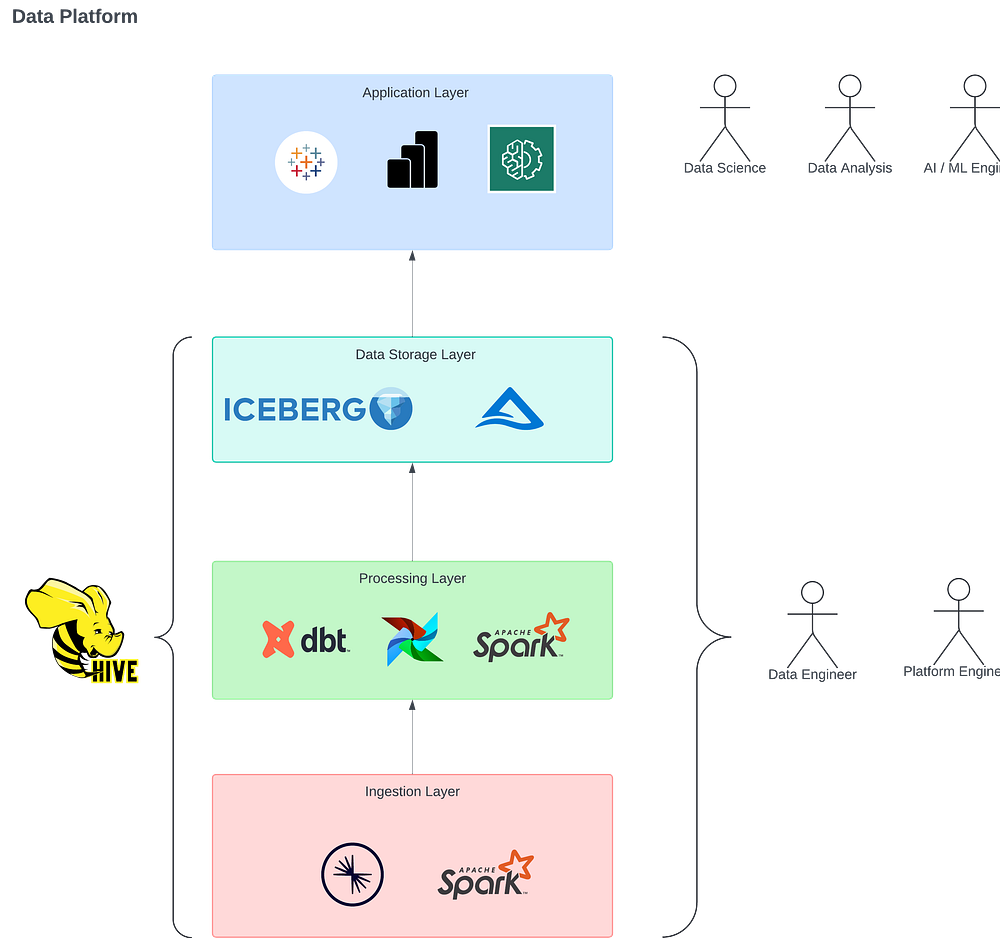
As data ecosystems continue to evolve and scale, the role of Hive Metastore becomes even more important to modern data architecture. Below is the overview of Hive Metastore’s main role and its value:
- Centralised Data Management: at its core, HMS serves as a metadata repository. It stores essential information for tables in the data platform: Table definitions (table, columns, and data types), Table partitions (for efficient querying and data versioning) and history (for Delta Lake)
- Seamless integration across Data Platform: HMS acts as the bridge between layers, ensuring that all the services in the Ingestion, Processing, and Data Storage Layer share a common data access pattern.
- Data Governance: By acting as a single source of truth for metadata, HMS ensures Data access control, auditing, and consistency across different layers of the data architecture.
The Future of Hive Metastore
As of today, solutions like Open Metadata and Databricks Unity Catalog are making strides in the metadata management space, serving various use cases. PepsiCo, managing over 6 petabytes of data globally, has leveraged Unity Catalog and Hive Metastore to streamline the onboarding process for more than 1,500 active users and enable unified data discovery for over 30+ digital product teams, supporting BI & AI applications.
“Databricks Unity Catalog is now an integral part of the PepsiCo Data Foundation, our centralized global system that consolidates over 6 petabytes of data worldwide. It streamlines the onboarding process for more than 1,500 active users and enables unified data discovery for our 30+ digital product teams across the globe, supporting both business intelligence and artificial intelligence applications.” — Bhaskar Palit, Senior Director, Data and Analytics @ PepsiCo
As the data ecosystem evolves, Hive Metastore’s role will remain critical. While current data architectures emphasise cloud-native solutions and a Data Mesh approach, HMS is poised to meet emerging demands, including AI-driven data management, near real-time data access, and streaming. For more insights, see the PepsiCo case study here.
We are also seeing new projects besides Databricks and Open Metadata join the metadata management market. These tools offer granular access control, seamless cloud integration with a modern stack, and better governance features. This means that we are likely to see more features follow suit and push the capabilities of what metadata management can bring, especially with AI capabilities.
Conclusion
PepsiCo’s example highlights the power of modern data management capabilities and demonstrates how large-scale data platforms can uplift global data strategy and governance.
As more enterprises adopt cloud-native data solutions and Data Mesh, metadata management services will continue to play a critical role in addressing challenges such as PII management, data access control, near real-time access, and scaling. With more tools like Open Metadata and MetaCat (Netflix) joining the space, the boundaries of metadata management will be pushed further, integrating new capabilities, including AI-driven solutions.
I hope you enjoyed reading about the Hive Metastore’s journey and how it has fundamentally changed how we manage and work with data, from the Hadoop days to the current era of Big Data and AI. This article highlighted HMS’s role and value in the metadata management world and its place in modern data architecture.
For more information, check out Hive Metastore Documentation, which talks about these capabilities in much more detail and is for those who want to dig into the how-to.
Key takeaways:
i) Streamline Data Governance Strategy for the organization
ii) Seamless Data integration across the Data Platform
iii) Centralised Data Management solution for complex data architecture
Reference
Aditya Auradkar, C. B. (2012). Data Infrastructure at LinkedIn. 2012 IEEE 28th International Conference on Data Engineering (ICDE) (pp. 1370–1381). Washington, D.C: IEEE.
Cockcroft, A. (2011, 07 27). OSCON Data 2011: Adrian Cockcroft, “Data Flow at Netflix”.
Databricks. (2024, 10 07). What is Unity Catalog? . Retrieved from Databricks:
DataValley. (2023, 2 21). Exploring the Power of Apache hive: A Comprehensive Overview.
Dehghani, Z. (2022). Data Mesh. O’Reilly Media, Inc.
Eva Tse, J. B. (2010, 3 20). Hive user group presentation from Netflix (3/18/2010).
Google Cloud. (2024, 10 15). Use the Cloud Storage connector with Apache Spark.
Open Metadata. (2021). Open Metadata Documentation.
The Hadoop Platforms Team. (2014, 5 17). Yahoo Betting on Apache Hive, Tez, and YARN.
Wikipedia. (2024, 7 2). Apache Hive
Credits
Special thanks to Pete Crawford, Timothy Napier, Jon McAuliffe, Kovid Rathee, Matt Dudley, Nicholas Burrage, Emerald Leung, for generously taking time out and providing feedback on this blog.