Git Commit: When AI Met Human Insight

Corin Lawson
Software Engineer
Corin Lawson
Software Engineer
A Journey Through Commit Message Generation
Introduction
Imagine tying up your hiking boots and grabbing your trail mix for an adventure through a coding landscape of commit messages. This is the journey I recently shared with my colleagues, exploring the peaks of quality, the valleys of inconsistency, and the potential for AI to help us navigate this treacherous terrain. Today, I’d like to take you on an extended version of this trek, diving deeper into the nuances and technical details of using AI to enhance our commit message practices.
The Commit Message Landscape
Our journey begins in Git Wood, where we encounter two contrasting specimens of commit messages. One is a paragon of clarity — informative, structured, and telling a complete story. It explains the why, what, and how of a change, providing crucial context for future developers. The other? A wild, untamed message — short, vague, and leaving us with more questions than answers.
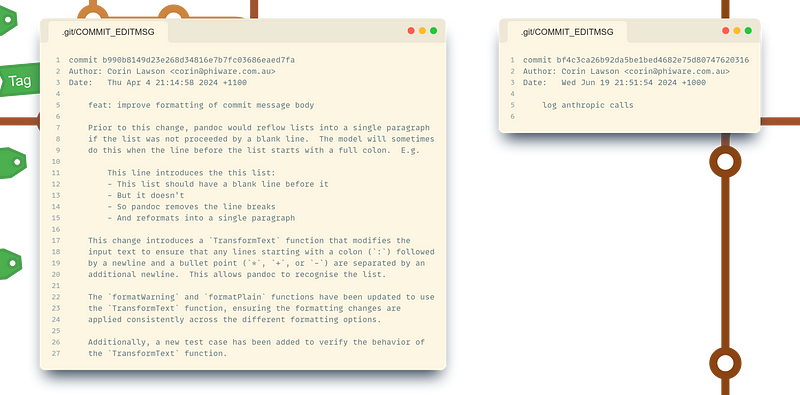
The author of these two messages is yours truly; I’m not proud. The body of the first starts with a clear statement of the problem, complete with an example, that motivates the need for the change, in this case, a new feature. This motivation is difficult to discern from the code alone. It’s followed by a description of the change, which could easily be reconstructed by reading the diff, but it is framed in terms that may not be immediately obvious from the code; for example, ‘bullet point’ has been defined as *, +, or -.
Names of variables and functions are explicitly mentioned, which allows the reader to orient themselves in the codebase without having to rely on the alphabetical ordering of the code files in the diff. Parenthetical changes, such as test cases, are also given their due. The discussion could have gone on with performance implications or future work, whatever was on the author’s mind at the time.
The second message provides no context, no explanation, and no guidance. It’s a dead end in the codebase. It’s an example of how inconsistent messaging can become a stumbling block for teams and contributors. Too often, I’ve called git blame in order to place myself in the author’s boots, only to find a list of mechanical changes with no narrative, context or rationale.
As Peter Hutterer once said, “A commit message shows whether a developer is a good collaborator.” Clear, informative commit messages not only demonstrate technical skills but also show respect for fellow team members. Personal experience has taught me the importance of writing better commit messages — not only for my own sanity but also for the benefit of my team and the project as a whole.
The Trusted Companion: Commit Templates
For the past seven years, a trusty commit template has been my guide through the coding wilderness. This template serves as a compass, prompting me to remember that a commit message is more than just a digital graffiti — it’s a crucial medium of communication. In the archaeological dig that is our codebase, it stands as a signpost, preserving the changes and their underlying motivations for future developers to follow.
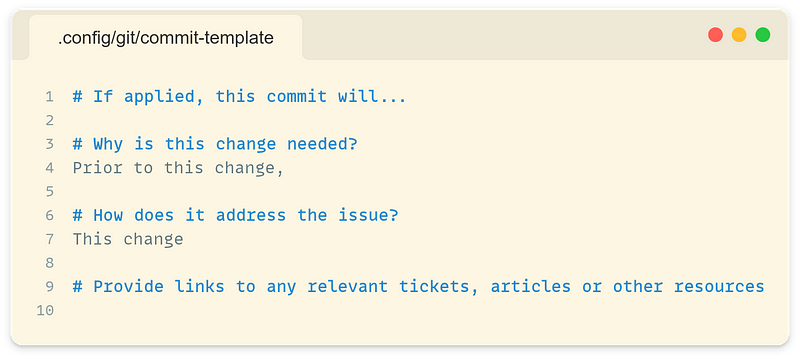
This template can be installed globally by running the following command:
git config --global commit.template /path/to/commit-template.txt
The template encourages better commit writing by structuring the commit message before opening an editor for the developer to make changes every time git commit is called. It helps to remind the developer that the “what” and “why” of the change needs to be clearly communicated, allowing more space for them to focus on providing context. However, even with guidelines in place, the pressures of time and context-switching often leads to specimens like the second message above.
The Spark: AI-Assisted Commit Messages
Given my consistent use of a commit template and the resulting corpus of structured messages, a question arose: Could AI help to address the challenges of consistency and quality in commit messages?
My journey into AI-assisted commit messages began with an ambitious plan to fine-tune a model on my own corpus of commit messages. However, I was struggling to work with the various Jupyter notebooks available with the hardware limitations of my local GPU. This was when a colleague introduced me to a technique called “Metaprompting.”

Metaprompting is a technique that uses a large language model to generate prompts for another model. It’s essentially a prompt for a prompt, created by the team at Anthropic as a starting point for best practices in prompt engineering with their largest Claude 3 model, Opus (at the time of prompting). It distills the collective wisdom of the team, their best practices and lessons learned, into a document that can be quickly consumed by Claude.
The metaprompt is structured using XML-like tags, allowing the model to draw connections between different components. It includes examples of good prompts (prompts within a prompt), sets the tone with a preamble, and provides instructions for writing the final prompt.
The Resulting Template
The output of this process was a prompt template designed to generate commit messages from git diffs. Interestingly, it included unexpected features like detecting leaked sensitive information and large binary files. The following is one of the examples generated by the model:
<example>
<diff>
diff --git a/src/main/java/com/example/MyClass.java b/src/main/java/com/example/MyClass.java
index 34c6f64..9f3a73e 100644
--- a/src/main/java/com/example/MyClass.java
+++ b/src/main/java/com/example/MyClass.java
@@ -5,6 +5,7 @@ public class MyClass {
private String password = "password123";
public void myMethod() {
System.out.println("Hello, world!");
+ System.out.println("Goodbye!");
}
}
</diff>
<sensitive-info-warning>
Warning: The diff contains sensitive information:
- Line 5: Hardcoded password found in the code
Please remove the sensitive information from the code and commit again.
</sensitive-info-warning>
</example>
This example improves upon my original commit template by automating key parts of the commit message creation process. It not only helps with consistency but also adds practical warnings about issues like sensitive information, reducing human error.
This example was followed by a handful more, somewhat lackluster examples, but it was a quick and easy start. Swapping out the examples for real diffs was a simple matter of copy-pasting a few choice diffs from my own projects. I continued to iterate on the template to focus more attention on personal preferences, such as the inclusion of the branch name and making reference to “Conventional Commits.” The final template looked like this:
<Instructions>
Here is the diff on the branch for the code changes you are committing:
<branch>
%s
</branch>
<diff>
%s
</diff>
Please carefully review the diff above.
In a <thinkthrough> section, analyse the changes in detail, considering:
- Analyse the overall purpose and context of the changes
- Identify any sensitive information like API keys, passwords, or personal data that should not be included in a commit
- Check if the diff includes large files over 50MB that may be better suited for Git Large File Storage (LFS)
- Note the specific modifications made to each file, function, class, variable etc.
- Consider the reasoning behind any architectural or implementation choices
- Identify any limitations, future TODOs, or other relevant notes about the changes
<sensitive-info-instructions>
If the diff contains sensitive information like API keys, passwords, auth tokens, or personal data:
- Do NOT include this information in the commit message
- Instead, output a message wrapped in <sensitive-info-warning> tags identifying the potential exposure
- Suggest removing the sensitive information from the diff and re-committing
</sensitive-info-instructions>
<large-files-instructions>
If the diff contains files larger than 50MB:
- Do NOT commit these files directly to the repo
- Instead, output a message wrapped in <large-files-warning> tags identifying the oversized files
- Suggest using Git LFS for those large files and link to setup instructions: https://git-lfs.github.com
</large-files-instructions>
<commit-message-instructions>
If the diff does not contain sensitive information or large files, write a clear and concise commit message explaining the changes, following these style guidelines:
- Use a short and descriptive subject line of 50 characters or less
- Use 'conventional commits' style, e.g. "feat:", "fix:", "chore:", etc.
- Use the imperative mood in the subject line (e.g. "introduce feature" not "added feature")
- Do not end the subject line with a period
- Separate the subject line from the body with a blank line
- Wrap the body at 72 characters
- Use the body to explain what and why, not just how
- Use the body to explain:
- The high-level motivation and context of the changes
- What the changes actually are, at a high level
- The rationale behind significant decisions
- Maintain a professional and positive tone; avoid humour or casual language
<scratchpad>
1. Review the diff carefully to understand the scope of the changes made
2. Summarize the key changes in a concise one-liner of less than 50 characters
3. Add 5-15 sentences with additional context on the changes and the reasoning behind them
</scratchpad>
Write out your complete commit message (subject line and body) inside <commit-message> tags. Make sure to include a blank line between the subject line and body.
</commit-message-instructions>
</Instructions>
Implementation: The Go Program
To integrate this AI-generated prompt into my git workflow, I developed a Go program. This tool captures the git diff, sends it to Claude 3 Haiku (a smaller, faster version of the Claude 3 family), and writes the model’s output back to disk. When installed as the prepare-commit-msg git-hook, all this is performed automatically for each commit and presented in the user’s default editor for review and revision. The project has been open sourced (under the MIT license) and is available on GitHub.
Using this tool is like having a super-intern who excels at summarizing changes but lacks a broader project context. It’s particularly adept at explaining the ‘what’ and ‘how’ of changes but struggles with the ‘why.’ In roughly 1-in-3 commits it will attempt to write the Prior to this change section, although it’s a guess, it strikes me as a highly educated guess. At the very least, it’s a good starting point for the author to fill in the blanks and provide the context that is not available to the model.
Cost Analysis
One of the pleasing aspects of this experiment was its cost-effectiveness. Running this tool daily for a month costs only about ten cents.
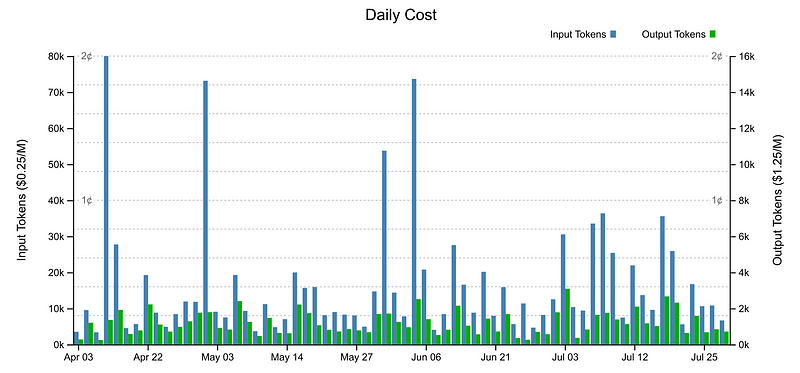
The chart above shows the daily cost of running the tool over four months. The API is metered by the number of tokens sent to the model (input tokens) and the number of tokens received from the model (output tokens). The input and output tokens are charged at different rates, with the output tokens being five times more expensive than the input tokens at USD$1.25 per million tokens. The number of output tokens is plotted on the right-hand axis of the chart, which is scaled by the same factor of 5 so that the cost and output tokens are on the same scale.
On any given day, the cost (not just the absolute number of tokens) of the input tokens is greater than the output tokens, despite the output tokens being more expensive.
Insights After Four Months
After using this tool for four months, I’ve gathered valuable insights:
- Time Savings: The tool has consistently saved me minutes on each commit.
- Danger of Complacency: There’s a risk of overlooking the crucial ‘why’ aspect of changes.
- Synergy with Other Tools: Interestingly, GitHub Copilot often enhances the AI-generated messages, picking up on context and the ‘thinkthrough’ analysis.
This experiment highlighted a crucial point: while AI can significantly aid with consistency and technical summaries, it cannot replace human insight. The ‘why’ behind our changes — the business context, user feedback, or strategic decisions — remains a uniquely human contribution.
In my experience, this tool outperforms GitHub Copilot’s default settings for commit message generation. However, it’s worth noting that tools like Conventional Commits and Commitizen offer different advantages in terms of standardization and team-wide adoption.
Future Directions
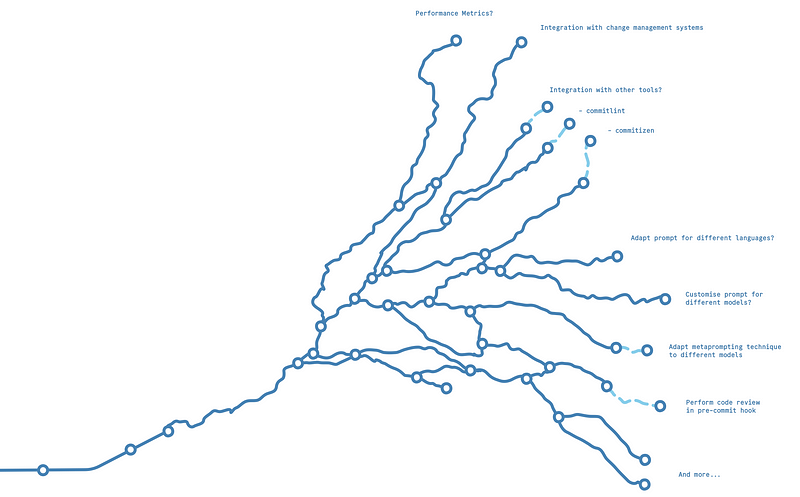
As we look to the horizon, several exciting possibilities emerge:
- Quality Tracking: Developing methods to track commit message quality over time.
- Integration with Project Management Tools: Extracting the ‘why’ from tools like Jira or GitHub issues.
- Workflow Integration: Exploring compatibility with tools like commitlint or commitizen.
- Customization: Tailoring the prompt to specific teams or projects.
- Model Exploration: Adapting the approach to cheaper or more powerful AI models.
- Expanding Applications: Applying metaprompting techniques to other development tasks, such as code reviews.
Conclusion
Our journey through the landscape of AI-assisted commit messages has shown how beneficial AI can be in maintaining consistency and detail in commit messages. However, it also underscores the irreplaceable value of human insight. As we continue to explore this terrain, the key lies in finding the right balance: using AI to handle routine aspects while allowing humans to focus on providing essential context and reasoning.
As we close this chapter of our adventure, I invite you to share your thoughts and experiences. How do you ensure quality in your commit messages? As AI takes on more routine tasks, what uniquely human skills should developers focus on cultivating to stay ahead in the evolving landscape of software development?